

As language models expand in size and complexity, the resources required for their training and deployment also increase. While large-scale models can perform exceptionally well across various benchmarks, they often remain beyond the reach of many organizations due to infrastructure constraints and high costs. This discrepancy between capability and deployability poses a practical challenge, especially for businesses aiming to integrate language models into real-time systems or cost-conscious environments.
In recent years, small language models (SLMs) have surfaced as a viable solution, offering reduced memory and compute requirements without significantly sacrificing performance. However, many SLMs face challenges in delivering consistent results across diverse tasks, and their design often involves trade-offs that can limit their generalization or usability.
ServiceNow AI Introduces Apriel-5B: Advancing Practical AI at Scale
To address these issues, ServiceNow AI has launched Apriel-5B, a new family of small language models emphasizing inference throughput, training efficiency, and cross-domain versatility. With 4.8 billion parameters, Apriel-5B is compact enough for deployment on modest hardware yet performs competitively across various instruction-following and reasoning tasks.
The Apriel family consists of two versions:
- Apriel-5B-Base, a pretrained model intended for further tuning or integration into pipelines.
- Apriel-5B-Instruct, an instruction-tuned variant optimized for chat, reasoning, and task completion.
Both models are provided under the MIT license, encouraging open experimentation and wider adoption for research and commercial purposes.
Key Architectural and Technical Features
Apriel-5B was trained on over 4.5 trillion tokens, drawing from a dataset designed to span multiple task categories like natural language understanding, reasoning, and multilingual abilities. The model employs a dense architecture optimized for efficient inference, featuring key technical elements such as:
- Rotary positional embeddings (RoPE) with a context window of 8,192 tokens, facilitating long-sequence tasks.
- FlashAttention-2, which speeds up attention computation and enhances memory utilization.
- Grouped-query attention (GQA), reducing memory usage during autoregressive decoding.
- Training in BFloat16, ensuring compatibility with modern accelerators while preserving numerical stability.
These architectural choices enable Apriel-5B to remain responsive and speedy without relying on specialized hardware or massive parallelization. The instruction-tuned version was refined using curated datasets and supervised techniques, allowing it to excel in instruction-following tasks with minimal prompting.
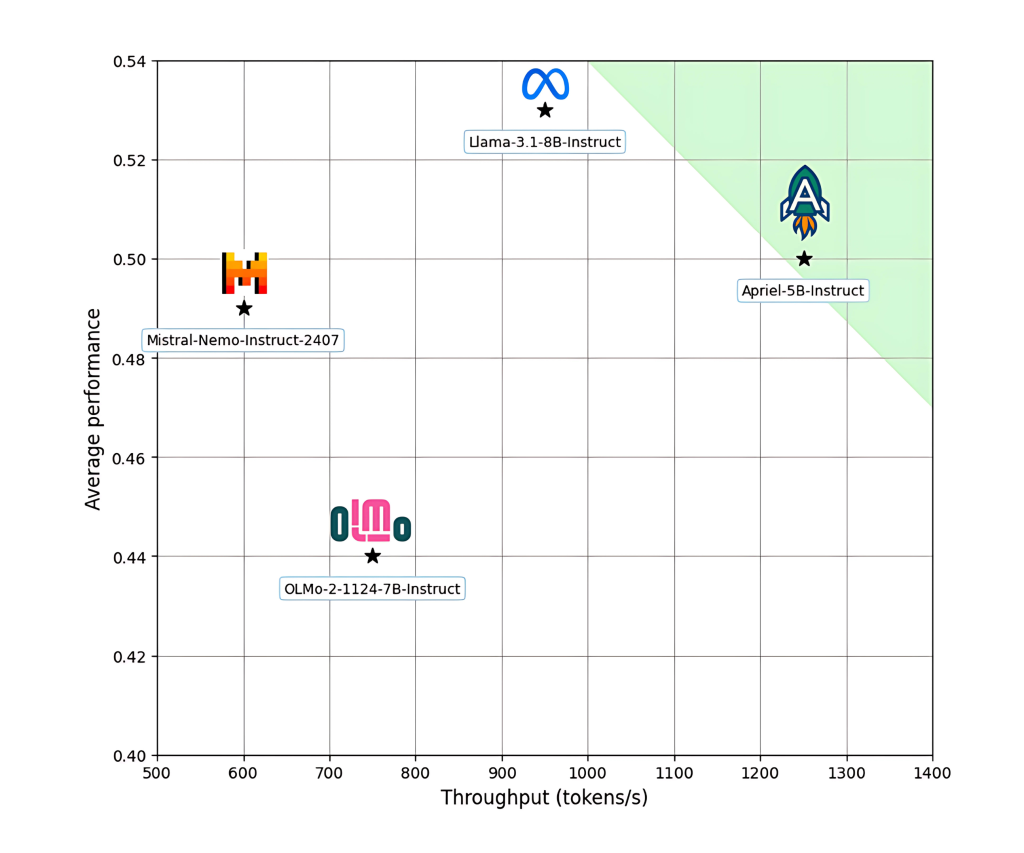
Evaluation and Benchmark Performance
Apriel-5B-Instruct was assessed against several prominent open models, including Meta’s LLaMA 3.1–8B, Allen AI’s OLMo-2–7B, and Mistral-Nemo-12B. Despite its smaller size, Apriel performs competitively across various benchmarks:
- Outperforms OLMo-2–7B-Instruct and Mistral-Nemo-12B-Instruct in general-purpose tasks.
- Excels beyond LLaMA-3.1–8B-Instruct in math-focused tasks and IF Eval, which assesses instruction-following consistency.
- Demands significantly fewer compute resources—2.3x fewer GPU hours—compared to OLMo-2–7B, highlighting its training efficiency.
These results indicate that Apriel-5B strikes a productive balance between lightweight deployment and

Katy Perry Explora el Espacio para Lanzar su Gira: Viajar al Cosmos, el Nuevo “El Hormiguero
El ingenioso pero ilícito atajo de los vendedores chinos en Amazon frente a los aranceles de EE.UU.
Related Posts

Pope Leo XIV Warns: AI Poses Risks to Human…
mayo 12, 2025
ChatGPT: The AI That Fuels Hubris and Family Fears
mayo 9, 2025


